CodeGeeX是智谱AI旗下的代码生成大模型,2022年9月发布第一代模型,以每半年更新一代模型的迭代速度不断进化,致力于探索大模型代码生成能力的上限。基于模型打造的CodeGeeX智能编程助手,不仅支持代码补全、代码注释、代码修复、代码翻译等基础功能,还支持联网代码问答、代码解释器、检索增强等进阶实用功能。CodeGeeX对个人用户完全免费,在各种主流IDE均可免费下载使用。目前CodeGeeX的个人用户数量已经超过100万,企业版本也已经广泛应用于科技、金融、医疗和制造等多个行业,在中国信通院组织的代码大模型首轮评估中获得当前最高评级,成为国内首批通过该项评估的大模型之一。为了让更多人体验到CodeGeeX的强大能力,我们正式发布CodeGeeX4系列模型的开源版本:CodeGeeX4-ALL-9B,集代码补全和生成、代码问答、代码解释器、工具调用、联网搜索、项目级代码问答等所有能力于一体的代码大模型,是目前百亿(10B)参数以下性能最强、最全能的代码大模型。
模型的核心功能Demo和使用教程已经在GitHub上开源,模型权重可在HuggingFace、ModelScope、WiseModel等大模型平台下载。

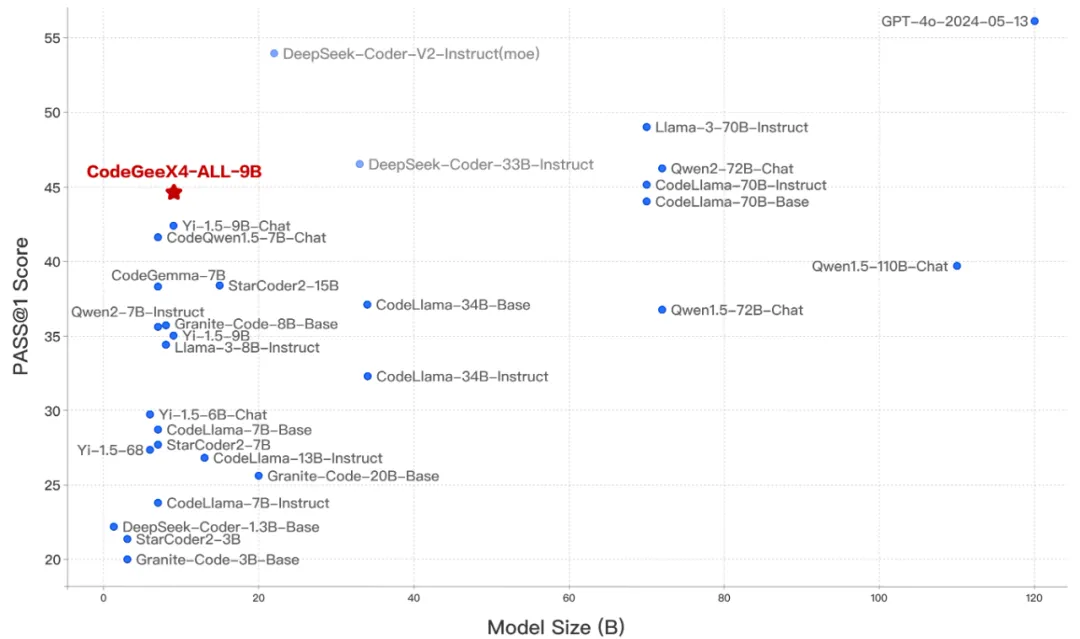
一、CodeGeeX4-ALL-9B:百亿参数以下性能最强的全能代码模型CodeGeeX4-ALL-9B作为最新一代CodeGeeX4系列模型的开源版本,在GLM4强大语言能力的基础上继续迭代,大幅增强代码生成能力。使用CodeGeeX4-ALL-9B单一模型,即可支持代码补全和生成、代码解释器、联网搜索、工具调用、仓库级长代码问答及生成等全面功能,覆盖了编程开发的各种场景。CodeGeeX4-ALL-9B在多个权威代码能力评测集,如NaturalCodeBench、BigCodeBench上都取得了极具竞争力的表现,是百亿参数量级以下性能最强的模型,甚至超过数倍规模的通用模型,在推理性能和模型效果上得到最佳平衡。1. 性能表现评测BigCodeBench测试结果显示,CodeGeeX4-ALL-9B在同等尺寸下效果最好:
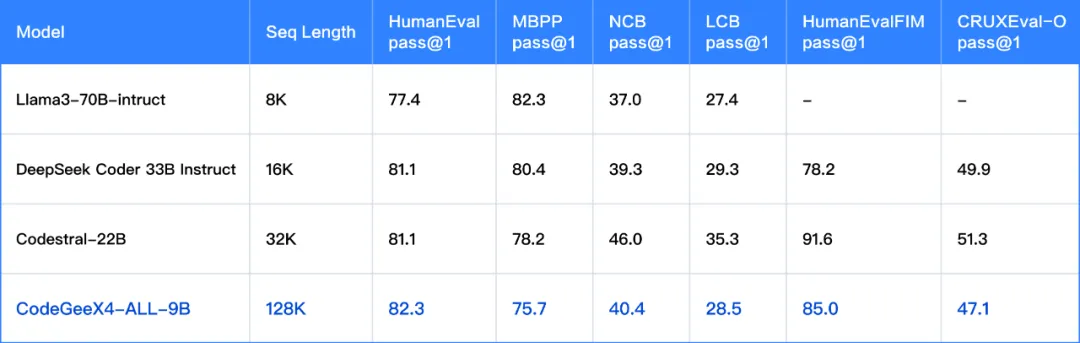
在其他代码生成、补全、推理测试集上,CodeGeeX4-ALL-9B取得了与更大规模模型接近的水平:
2. CodeGeeX4-ALL-9B上下文处理能力达到了128K,相较于上一代模型增长8倍!
对于参数量10B以下的代码大模型,从海量的代码中准确提取信息是一个关键性的挑战。CodeGeeX4-ALL-9B升级支持128K上下文,使其能够处理和利用更长代码文件、甚至是项目代码中的信息,有助于模型更深入理解复杂和细节丰富的代码。基于更长的上下文,CodeGeeX4-ALL-9B可以处理更复杂的项目级任务,在输入显著变长的情况下,依然能准确回答不同代码文件中的内容,并对代码作出修改。在“大海捞针”(Needle In A Haystack, NIAH)评估中,CodeGeeX4-ALL-9B模型展示了其在处理长达128K的上下文中进行代码的嵌入和检索能力,实现了100%的检索准确度。
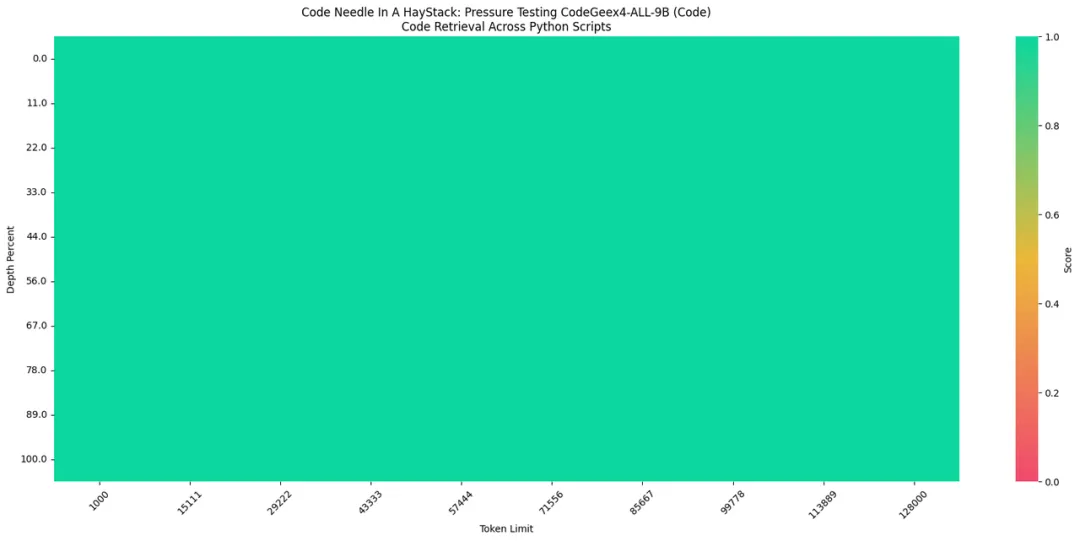
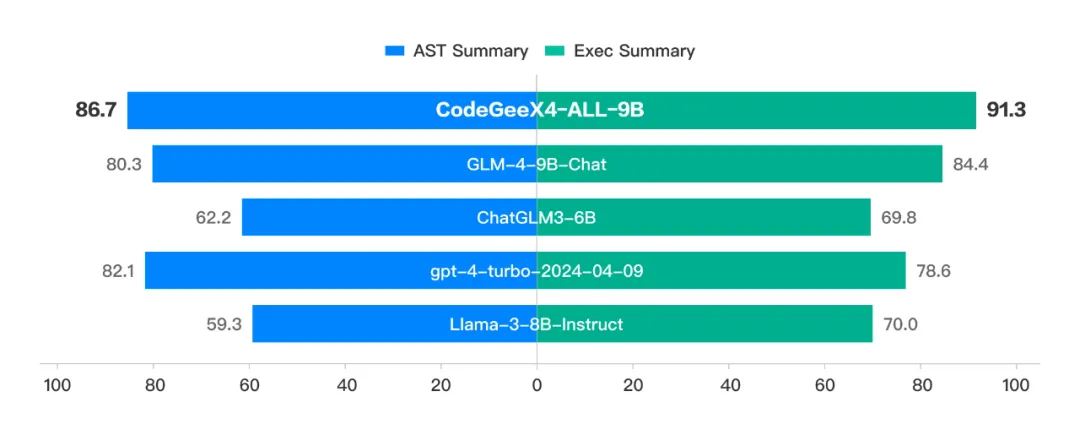
上面这张图,表现的是在一个全部由Python代码组成的测试集中,插入一个赋值语句,如:zhipu_codemodel = “codegeex”(Needle)。测试模型是否可以正确回答出zhipu_codemodel的值,CodeGeeX4-ALL-9B 100%完成任务。3. CodeGeeX4-ALL-9B 支持 Function Call 能力CodeGeeX4-ALL-9B是目前唯一一个实现Function Call的代码大模型。Berkeley Function Calling Leaderboard是第一个可全面评估大模型函数调用能力的测试集。其中AST数据集是评估模型对Java、JavaScript、Python程序的调用能力;Excecutable数据集是评估模型对真实场景API的函数调用能力。CodeGeeX4-ALL-9B在Berkeley Function Calling Leaderboard上进行了全面的测试,包括各种形式的函数调用、不同的函数调用场景以及函数调用可执行性的测试,得到了以下结果:在AST和Exec测试集中成功调用率超过90%。
详情请看:https://mp.weixin.qq.com/s/iS7do8htAe74TCkFHa4zSg